本研究围绕热门图书推荐系统展开,主要涵盖系统架构设计、核心功能开发及关键技术实现三方面内容。
在系统架构设计上,采用B/S开发模式,基于SpringBoot框架构建后端服务,实现系统的模块化开发与灵活部署。数据库选用MySQL,合理设计用户表、图书表、论坛表等核心数据库表结构,建立表间关联关系,确保数据存储的完整性与高效性。前端采用响应式设计,适配不同终端设备,为用户提供流畅的交互体验[3]。
核心功能开发中,管理员功能模块是重点。管理员可对用户进行全生命周期管理,包括注册审核、权限分配、账号禁用等操作,保障系统用户数据安全;图书信息管理功能支持图书基本信息录入、分类管理、热门标签设置,结合Spider爬虫获取的图书数据进行清洗与整合,确保图书资源的丰富性与准确性;图书论坛管理模块实现帖子审核、评论管理、违规处理等功能,维护论坛良好交流秩序。此外,系统还将设计智能推荐算法,结合用户阅读历史、收藏记录、论坛互动等数据,为用户精准推送热门图书。在关键技术实现方面,利用Spider爬虫技术,从图书电商平台、资讯网站等多渠道抓取图书数据,并通过数据预处理技术对采集的数据进行去重、纠错;SpringBoot框架实现业务逻辑分层开发,提高系统的可维护性与扩展性;MySQL的索引优化、事务管理等技术保障数据的高效读写与一致性,为系统稳定运行提供支撑[4]。
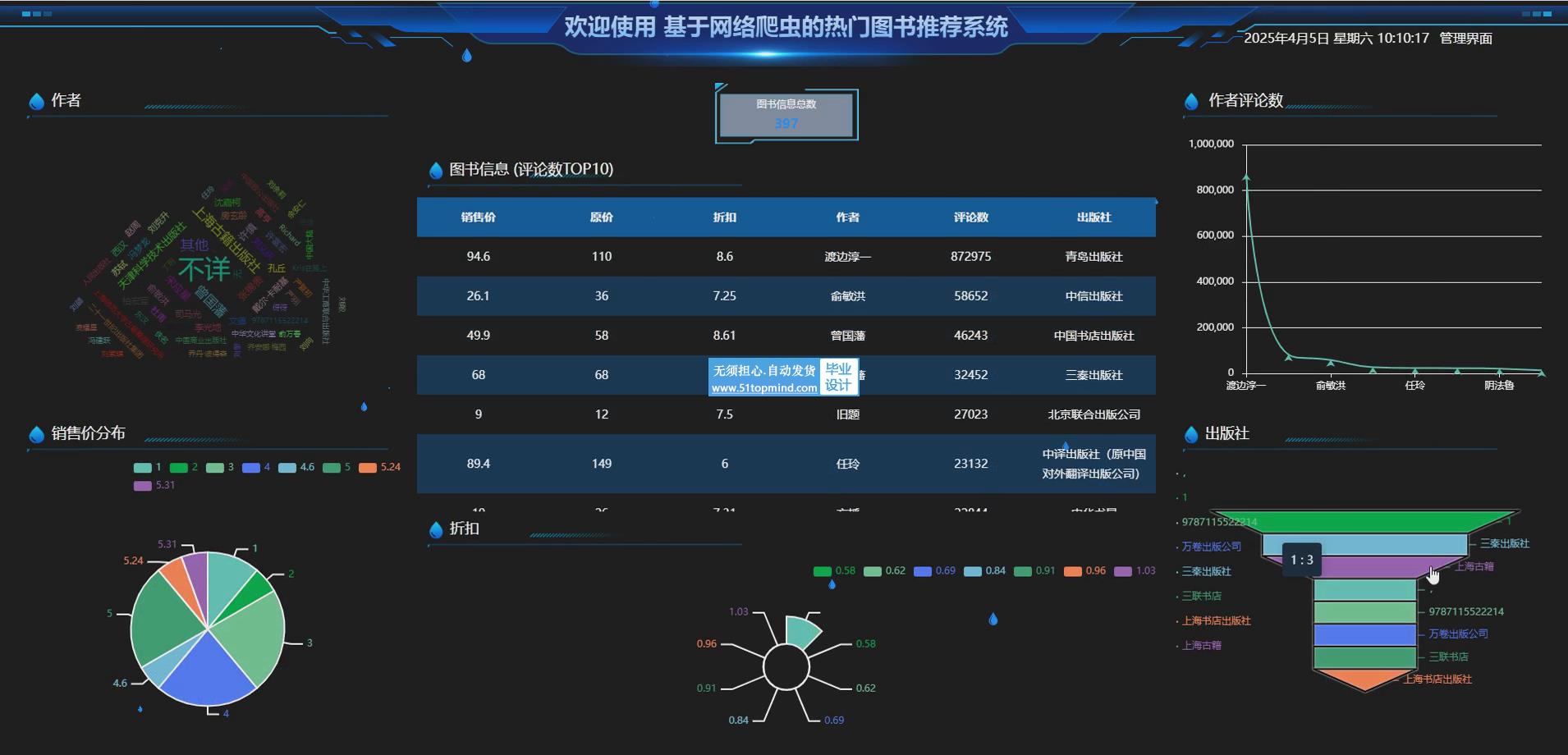
在当今数字化信息爆炸的时代,人们对获取优质图书资源的需求日益增长,而如何精准地推荐热门图书成为亟待解决的问题。传统的图书推荐方式存在信息滞后、推荐不够个性化等不足,难以满足用户多样化的需求。因此,开发一个高效、智能的热门图书推荐系统具有重要的现实意义。
本热门图书推荐系统基于B/S开发模式,采用SpringBoot框架进行后端开发,实现了系统的快速搭建和高效运行。数据库选用MySQL确保了数据的稳定存储和高效访问。同时,利用Spider爬虫技术从互联网上抓取丰富的图书相关信息,为推荐系统提供充足的数据支持。系统的功能丰富,管理员能够对用户信息进行全面管理,包括用户的注册、登录、权限设置等;对图书信息进行细致维护,涵盖图书的添加、修改、删除等操作;还能对图书论坛进行管理,保障论坛的有序运行,促进用户之间的交流与互动。
该热门图书推荐系统的开发,不仅为用户提供了便捷、精准的图书推荐服务,满足了用户个性化的阅读需求,提升了用户的阅读体验;也为图书行业的发展提供了新的思路和方法,有助于推动图书资源的有效传播和利用,促进文化的交流与传承。
关键词:热门图书推荐系统;Spring Boot框架;Spider爬虫;MySQL
目 录
摘 要 I
Abstract II
目 录 III
1 绪 论 1
1.1研究背景 1
1.2 国内外研究现状 1
1.2.1 国外研究现状 1
1.2.2 国外研究现状 2
1.3 研究的主要内容 4
1.4 研究方法 4
2 系统相关技术 6
2.1 Java语言简介 6
2.2 MySQL数据库 6
2.3 Echarts介绍 7
2.4 Spring Boot框架 7
2.5 Spider爬虫 7
3 系统分析 9
3.1 可行性分析 9
3.1.1 经济可行性 9
3.1.2 技术可行性 9
3.1.3 运行可行性 10
3.2 需求分析 10
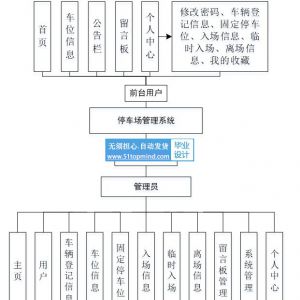
3.3 系统结构和流程设计 11
4 系统设计 15
4.1系统通用功能用例分析 15
4.2 系统设计主要功能 15
4.3 数据库设计 17
4.3.1 数据库设计规范 17
4.3.2 E-R图 17
4.3.3 数据表 21
5 系统实现 25
5.1前台用户功能模块 25
5.2 后台管理员功能模块 27
5.3 后台用户功能模块 30
5.4 看板展示 31
6 系统测试 32
6.1系统测试目的 32
6.2 系统功能测试 32
6.3 系统测试结论 35
结论 36
致谢 38
参考文献 39