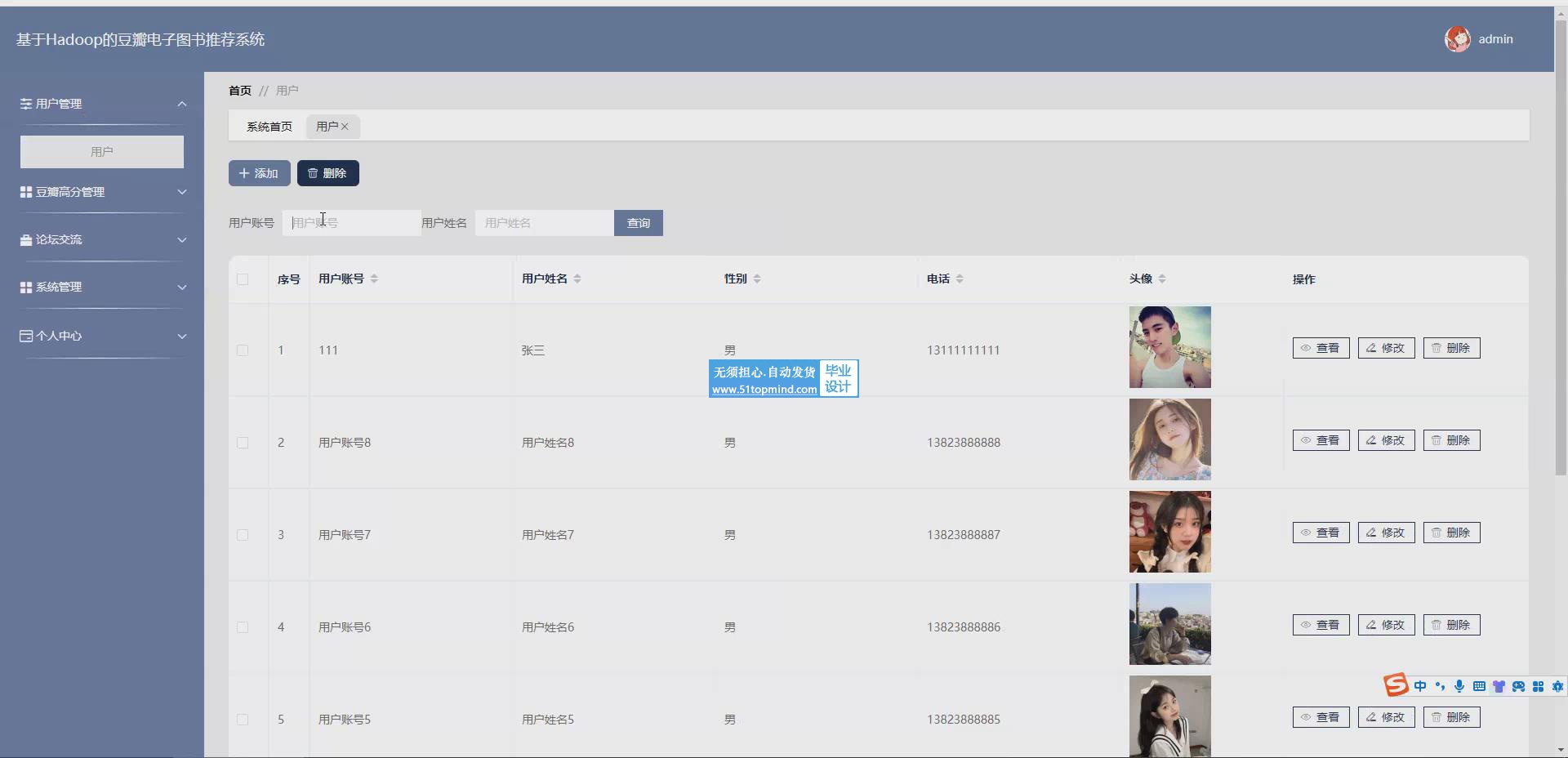
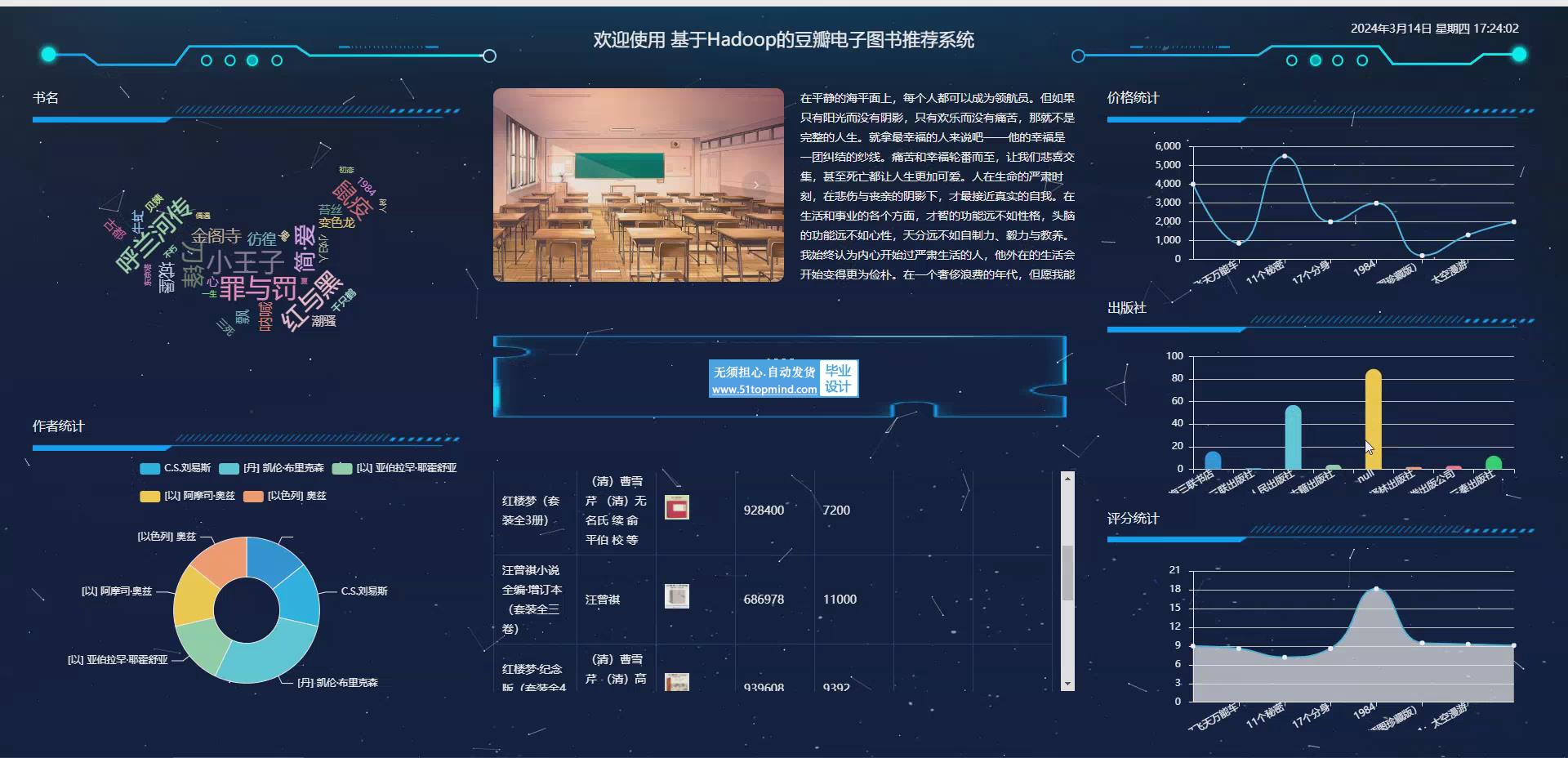
个性化推荐系统的研究起步较早,已经形成了一套较为成熟的理论体系和实践应用。特别是在以Hadoop为代表的大数据处理技术领域,由于其开源性和良好的扩展性,许多研究机构和商业公司纷纷采用Hadoop作为处理大规模数据集的基础平台。在电子图书推荐方面,国外的研究者通常利用数据挖掘、机器学习以及深度学习等技术,对用户的历史阅读行为、评分记录和社交网络活动进行分析,从而提取出有效的特征用于推荐算法的设计。协同过滤算法因其简洁有效而被广泛应用。为了提高推荐的准确性和多样性,研究者还不断探索融合内容推荐和协同过滤的混合推荐方法。随着移动互联网的发展,移动端的图书推荐也成为了研究的热点,这要求推荐系统不仅要有高精度,还要具备实时性,以适应移动环境下用户的即时需求。在此过程中,Hadoop生态系统中的其他工具如Hive、HBase等也被广泛应用于数据的存储和查询,极大地丰富了推荐系统的功能和应用范围。随着开数字化阅读的普及,豆瓣电子图书推荐系统应运而生,旨在为用户提供个性化的阅读体验。基于Hadoop的强大数据处理能力,该系统能够有效处理海量用户数据和书籍信息,通过复杂的算法模型为用户推荐高质量的内容。管理员功能涵盖用户管理、豆瓣高分管理等,确保了平台的高效运营。用户个人中心则提供修改密码、我的发布等服务,增强了用户体验。整体上,该推荐系统不仅提升了用户的阅读便利性,也促进了知识分享与文化交流。
根据本系统的基本设计思路,本系统在设计方面前台采用了java技术等进行基本的页面设计,后台数据库采用MySQL。本系统的实现为豆瓣电子图书推荐系统的运行打下了基础,为豆瓣电子图书推荐提供良好的条件。
最后我们通过需求分析、测试调整,与豆瓣电子图书管理的实际需求相结合,设计实现了豆瓣电子图书推荐系统。
关键词:电子图书;java;MySQL数据库
目 录
目 录 4
第1章 概述 6
1.1 课题研究背景与意义 6
1.2系统研究现状 6
1.3本文的组织结构 7
第2章开发技术 9
2.1 JAVA语言 9
2.2 SpringBoot框架 9
2.3 MYSQL数据库技术 9
2.4协同过滤推荐算法 10
2.5 Hadoop介绍 10
2.6 Scrapy介绍 11
2.7 B/S结构简介 11
第3章 系统分析 12
3.1系统总体分析 12
3.2系统可行性分析 12
3.3系统功能分析 13
3.4 系统流程分析 14
3.4.1 登录流程 14
3.4.2 添加信息流程 14
3.4.3 删除流程 15
第4章 系统设计 16
4.1系统功能设计 16
4.2数据库的设计 16
4.2.1数据库E-R图 16
4.2.2数据库表 17
第5章 系统实现 22
5.1前台功能实现 22
5.1.1系统首页页面 22
5.1.2个人中心 23
5.2管理员功能模块实现 24
第6章系统测试 28
6.1系统测试的重要性 28
6.2软件测试过程 28
6.3性能测试 28
6.4用户模块测试 28
总结与展望 30
参 考 文 献 31
致谢 33