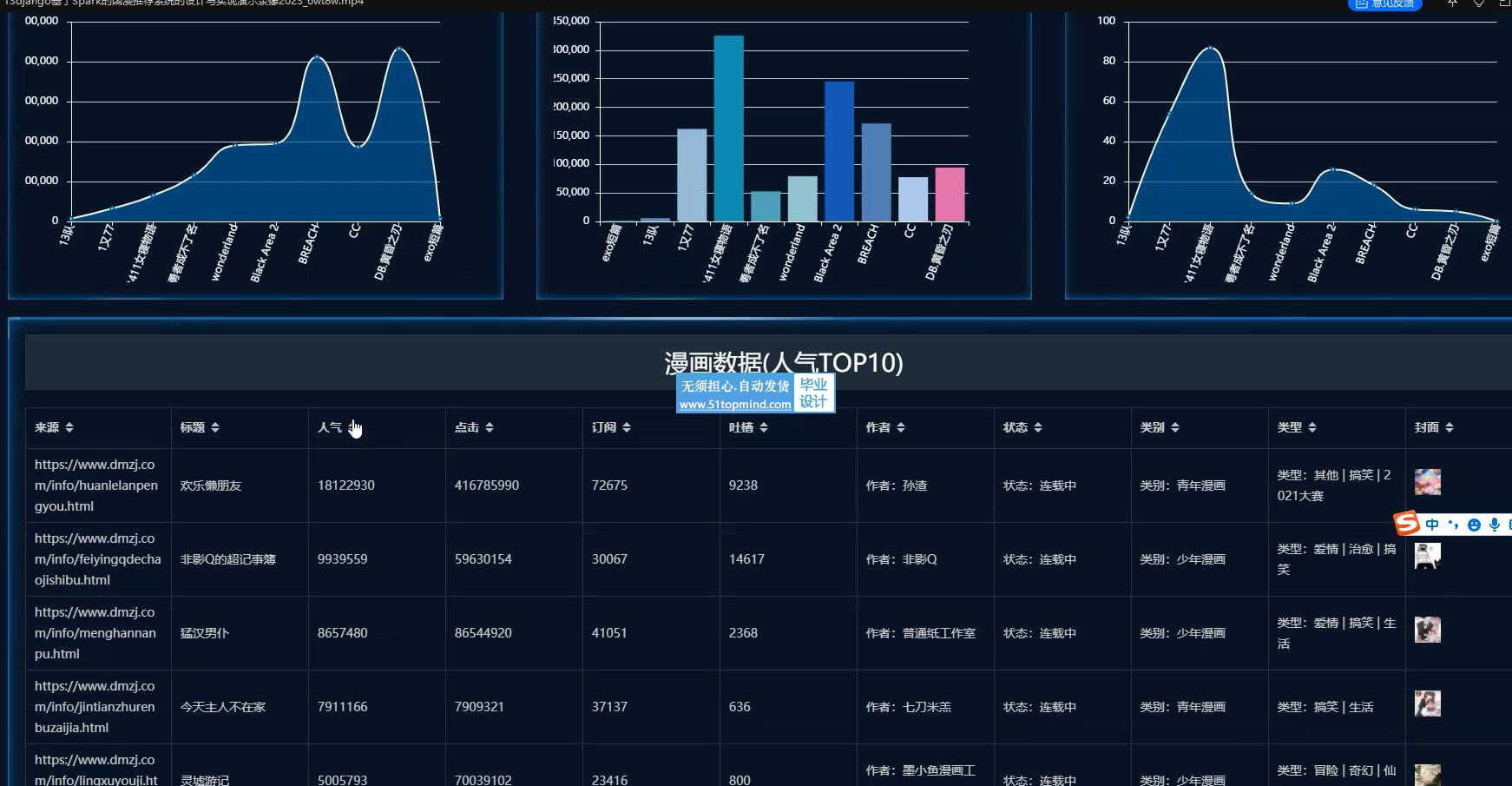
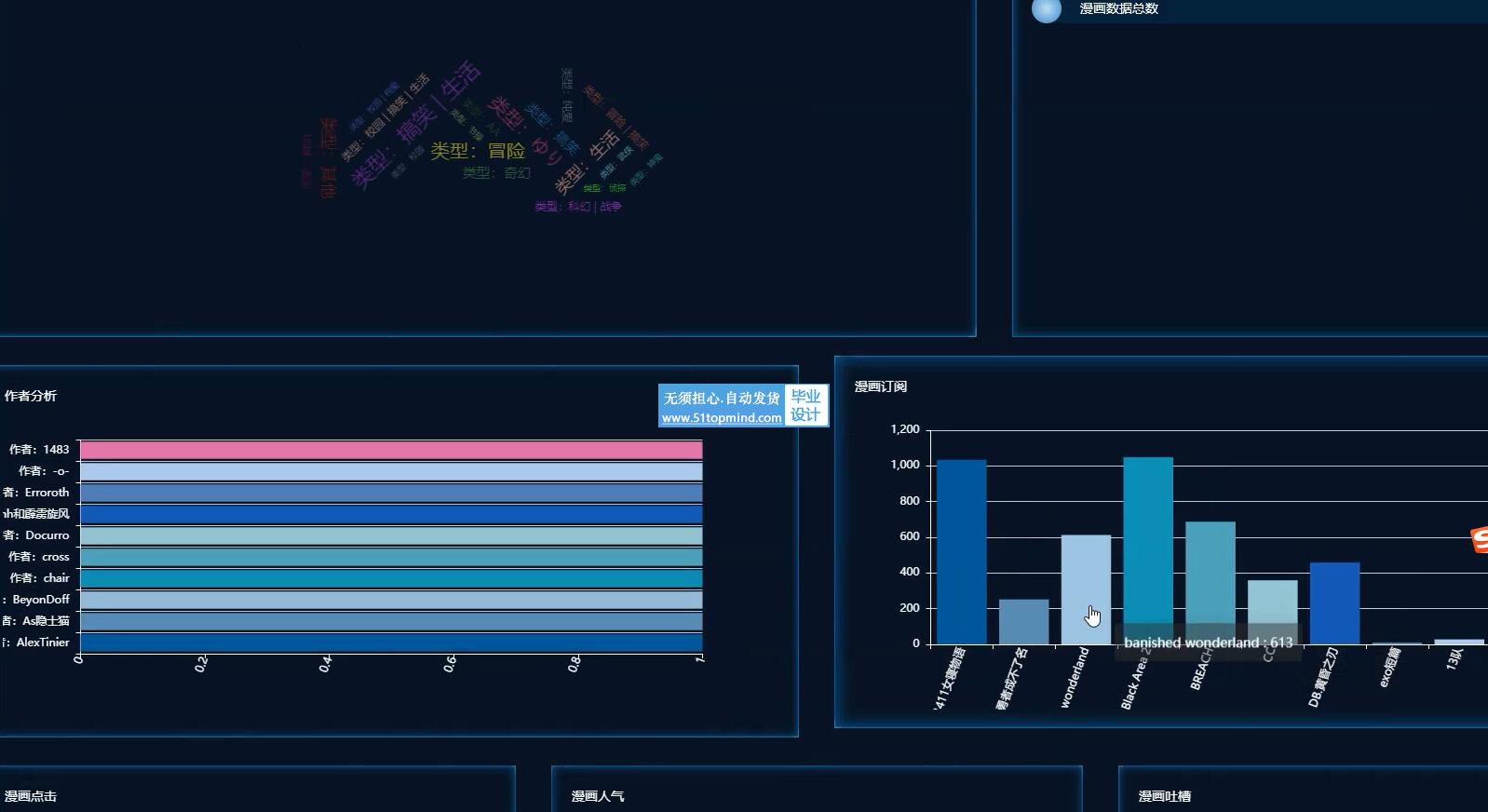
本文从国漫推荐管理的实际需要出发,为降低系统的耦合性,采用DJANGO框架集完成了系统总体架构的设计,以提高系统的重用性、可适用性及可维护性。
这个系统的设计主要包括系统页面的设计和方便用户互动的后端数据库,在开发后需要良好的数据处理能力、友好的界面和易用的功能。
数据要被工作人员通过界面操作传输至数据库中。通过研究,以Mysql数据库和Python技术,以pycahrm为开发平台,采用Django架构,建立一个提供个人中心、漫画数据管理、系统管理等必要功能的、稳定的国漫推荐系统。
关键词:国漫;Django框架;Mysql数据库
.3 Hadoop介绍
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。主要有以下优点:
(1)高可靠性。Hadoop按位存储和处理数据的能力值得人们信赖。
(2)高扩展性。Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
(3)高效性。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。高容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
(4)低成本。与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市相比,hadoop是开源的,项目的软件成本因此会大大降低。
2.4 Scrapy介绍
Scrapy是一个抓取系统数据和提取结构化数据的框架,它可以应用在广泛的应用中:Scrapy通常用于一系列应用,包括数据挖掘、信息处理或存储历史数据。使用Scrapy框架实现一个爬虫程序通常非常简单,抓取给定系统的内容或图像。
虽然Scrapy是为屏幕抓取(或者更准确地说是网页抓取)而设计的,但它也可以用于访问api以提取数据。
目 录
1 绪 论 1
1.1开发背景 1
1.2国内外研究现状和发展趋势综述 1
1.3开发设计的意义及研究方向 1
2 系统开发技术 3
2.1 Python可视化技术 3
2.2 Django框架 3
2.3 Hadoop介绍 3
2.4 Scrapy介绍 4
2.5 IDEA介绍 4
2.6 B/S架构 4
2.7 MySQL数据库介绍 5
3系统分析 7
3.1整体分析 7
3.2功能需求分析 7
3.3 系统可行性分析 7
3.3.1技术可行性 7
3.3.2经济可行性 8
3.3.3操作可行性 8
3.4系统流程分析 8
3.4.1操作流程 8
3.4.2添加信息流程 9
3.4.3删除信息流程 10
4 系统设计 11
4.1 系统体系结构 11
4.2 系统总功能结构设计 11
4.3 数据库设计 12
4.4 数据表 13
5 系统详细设计 16
5.1系统登录实现 16
5.2管理员模块实现 16
6 系统测试 19
6.1 运行环境 19
6.1.1软件平台 19
6.1.2 硬件平台 19
6.2 测试过程 19
6.2.1 界面测试 19
6.2.2 功能测试 19
6.2.3系统的测试环境 20
结 论 21
参考文献 22
致 谢 23