网络爬虫能够定向抓取数据,在杂乱无序的数据中寻找有用的数据,数据可视化分析在网络爬虫的基础上能够从大量的网络招聘信息当中提取到对自己有价值的数据,而不是全部的招聘信息都接收,然后再通过人为进行筛选。数据可视化分析通过图形的形式来表示数据,能够在海量的招聘信息中直观的展示信息,增加了数据的灵活性,让使用其系统的用户能够高效的理解和分析招聘信息的内容,能够在最快的时间内获取自身需要的信息,能够让招聘信息更加的明确可靠。让公司的HR和应聘者了解到不同学历和不同工作经验对应的薪资水平,企业用人单位能在这个数据当中了解目前企业招聘的现状,不同层次的人才提供什么样子的待遇;应聘者能够实时了解在当今的招聘市场对人才的一个需求, 企业需要什么样的人才,更加针对性的去加强自身的专业技能,从而使得在求职工作的过程中更加的从容。
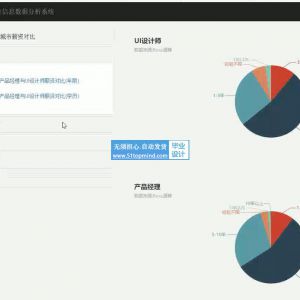
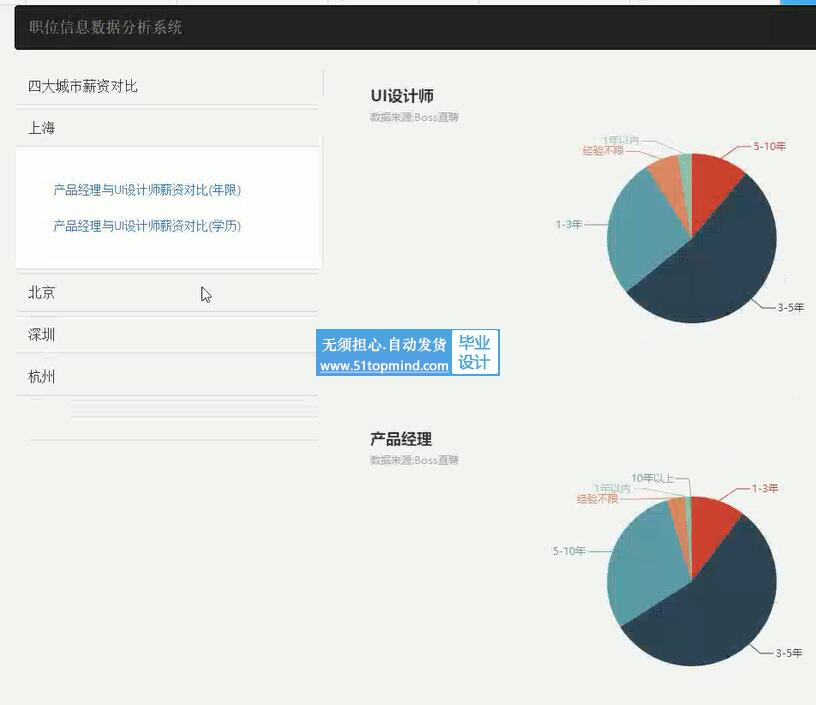
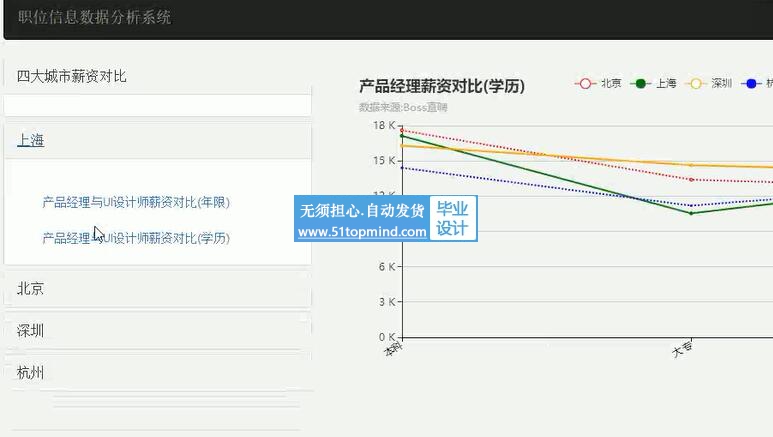
本项目主要利用python技术爬取BOSS直聘网站上的岗位信息,进行对比分析UI设计师与产品经理两个职位的趋势。爬取字段:工作地点,薪资范围,学历要求,工作经验,公司性质等。 模拟登陆BOSS直聘网站,爬取相关信息下载网页源码,采用beautifulsoup来提取数据,存储到数据库,以柱状图或饼状图形式对数据进行可视化分析得出结论。
1、利用request第三方工具包实现网页下载;
2、利用Beautiful Soup库过滤HTML标签,提取数据,并将数据存储到MySQL数据库中;
3、对抓取的数据进行数据清洗,主要除去空数据,让数据格式更规范;
4、利用Pandas对数据进行分析,以及使用Matlpotlib对分析后的数据进行可视化
目 录
摘要 1
abstract 1
目 录 2
1 绪论 4
1.1 开发背景 4
1.2 开发意义 4
2 开发技术介绍 4
2.1 Python介绍 4
2.2 Django介绍 5
2.3 xpath介绍 6
2.4 Vue介绍 6
2.5 Scrapy架构 6
2.6 开发环境搭建 7
3 系统设计 8
3.1 可行性分析 8
3.2 系统功能分析 9
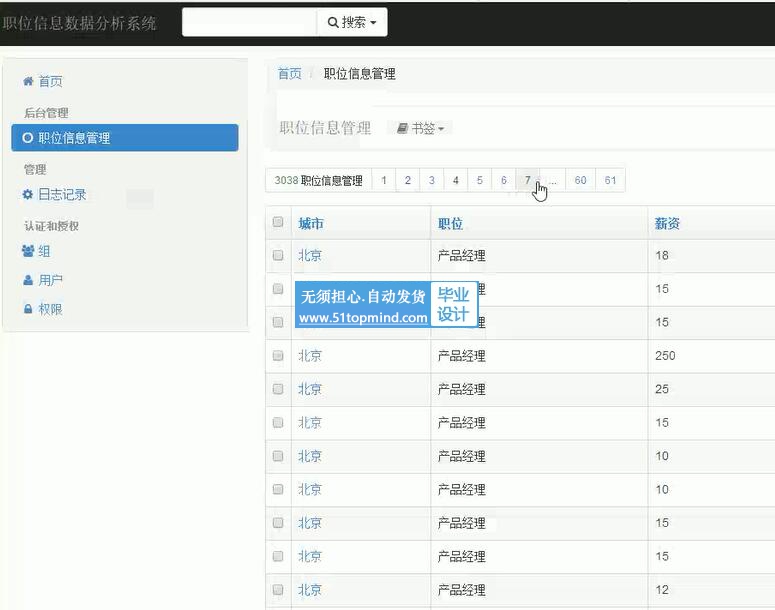
3.3 爬虫设计 9
3.4 功能模块设计 11
3.5 突破反爬虫设计 11
3.6 scrapy爬虫主要文件介绍 12
4 详细实现 13
4.1 数据抓取原理 13
4.2 数据抓取策略 13
4.3 数据可视化 13
4.3.1 薪资水平分析 14
4.3.2 学历水平分析 14
5 系统测试 15
5.1 软件测试的环境 15
5.2 测试的重要性 16
5.3 数据爬取功能测试 16
5.4 数据展示测试 16
结束语 17
参考文献 19
致谢 21